MPI: parallel computing 1/2
Introduction
The Message Passing Interface (MPI) is a C and Fortran library, built for running multiple processes in a distributed-memory fashion (using communication). It is flexible enough to also work with shared memory, if needed.
It offers lots of different functions, but you can already get programs working with only a minimal subset of about 6 commands.
Structure of a MPI program
The following structure applies to all programs:
- include the MPI header file
- declare variables
- MPI_Init(&argc, &argv);
- compute, communicate, etc.
- MPI_Finalize();
Putting everything together, we get the following structure:
// include the MPI header file
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv){
// declare variables
int my_rank, n_processes;
// init the MPI environment
MPI_Init(&argc, &argv);
// compute, communicate, etc.
// close the MPI environment
MPI_Finalize();
return 0;
}
Program execution
Running the program first requires building it via
mpicc program.c -o program.out
After that, running is as easy as just calling
mpirun -n 2 ./program.out
where -n specifies the number of processes.
MPI constants and handles
MPI Constants are usually integers and always capitalized (MPI_COMM_WORLD, MPI_INT, MPI_SUCCESS, etc.).
The constants MPI_COMM_WORLD and MPI_SUCCESS are also “handles”. A handle refers to internal MPI datastructes, i.e.
when you pass MPI_COMM_WORLD as an argument to a subroutine, MPI uses the refered communicator that includes all processes.
Rank
How to get your rank:
int my_rank;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
Comm_sz (number of processes)
How to get the size of the communicator:
int comm_sz;
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
Point-to-point communication
MPI_Send
- blocks
MPI_Send(
send_buf,
count,
dtype,
dest,
tag,
comm
);
MPI_Recv
- blocks
MPI_Recv(
recv_buf,
count,
dtype,
source,
tag,
comm,
status /* MPI_STATUS_IGNORE */
);
Collective Communication routines
- collective communication involves all processes of a communicator
- the routines can be classified into
one-to-many,many-to-oneandmany-to-manystructures
MPI_Barrier
- blocks all processes until every process called the Barrier routine
- semantics: synchronizes all processes (e.g. wait until a task is finished)
- use MPI_Barrier as little as possible to reduce overhead
Pseudocode:
- first send a Message in a cycle (P0 to P1, P1 to P2, …, P$_\text{n-1}$ to P0)
- after the cycle finishes let P0 broadcast to every process that all processes have reached the barrier
int MPI_Barrier(comm){
// declare variables
int my_rank, comm_sz;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
if(my_rank==0){
// process 0: send a message to process 1
MPI_Send(NULL, 0, MPI_INT, (my_rank+1)%comm_sz, 0, comm);
// and wait until the message went around the circle (in a 1d-torus fashion)
MPI_Recv(NULL, 0, MPI_INT, MPI_ANY_SOURCE, 0, comm, MPI_STATUS_IGNORE);
}
// all other processes
else{
// wait for all predecessors to reach the barrier so that the
// direct predecessor sends a message
MPI_Recv(NULL, 0, MPI_INT, MPI_ANY_SOURCE, 0, comm, MPI_STATUS_IGNORE);
// send a message to the process with the next rank
MPI_Send(NULL, 0, MPI_INT, (my_rank+1)%comm_sz, 0, comm);
}
// finally have all proccesses blocked until every other process reached the barrier
// by waiting for process 0 to get the message from the last rank and then calling
// broadcast to let every process return from this subroutine
MPI_Bcast(NULL, 0, MPI_INT, 0, comm);
return MPI_SUCCESS;
}
MPI_Bcast
- one-to-many
Example call:
MPI_Bcast(
message, /* buffer */
1, /* count */
MPI_INT, /* dtype */
3, /* root */
MPI_COMM_WORLD /* comm */
);
Pseudo-Implementation:
int MPI_Bcast(message, count, dtype, root, comm){
// declare variables
int my_rank, comm_sz;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// send the message to every process
if(my_rank==root){
for(int i=0; i<comm_sz; i++){
MPI_Send(message, count, dtype, i, 0, comm);
}
}
// all other processes: receive the message
else{
MPI_Recv(message, count, dtype, root, 0, comm, MPI_STATUS_IGNORE);
}
return MPI_SUCCESS;
}
MPI_Reduce
MPI_Reduce(
send_buf, /* send buffer */
recv_buf, /* receive buffer */
1, /* count */
MPI_INT, /* dtype */
MPI_SUM, /* operation */
3, /* root */
MPI_COMM_WORLD /* comm */
);
List of possible reduction operations:
- MPI_MIN/ MPI_MAX
- MPI_MINLOC/ MPI_MAXLOC (gives the min value and the index of the process, like argmin)
- MPI_SUM/ MPI_PROD
- MPI_LAND/ MPI_LOR (logical and/or)
- etc.
Pseudo-Implementation:
int MPI_Reduce(send_buf, recv_buf, count, dtype, operation, root, comm){
// declare variables
int my_rank, comm_sz;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
if(my_rank==root){
int result;
// collect items from every process
for(int i=0; i<comm_sz; i++){
MPI_Recv(recv_buf, count, dtype, i, 0, comm, MPI_STATUS_IGNORE);
// apply the reduction operation
result = operation(result, recv_buf);
}
// copy the result to the recv_buf
recv_buf = result;
}
// all other processes: send an item
else{
MPI_Send(send_buf, count, dtype, root, 0, comm);
}
return MPI_SUCCESS;
}
MPI_Allreduce
- all processes get all datapieces
- combine MPI_Reduce to do the reduction and MPI_Bcast to send the result to all processes
int MPI_Allreduce(send_buf, recv_buf, count, dtype, operation, comm){
// perform reduction to process 0
MPI_Reduce(
send_buf, /* send buffer */
recv_buf, /* receive buffer */
count, /* count */
dtype, /* dtype */
operation, /* operation */
0, /* root */
comm); /* comm */
// broadcast the result from proccess 0 to all other processes
MPI_Bcast(
recv_buf, /* result is stored in the recv_buf */
count, /* count */
dtype, /* dtype */
0, /* root */
comm); /* comm */
return MPI_SUCCESS;
}
MPI_Gather
- many-to-one
- the root process gets a piece of data from each process (including itself) and stores all the data in order of the ranks
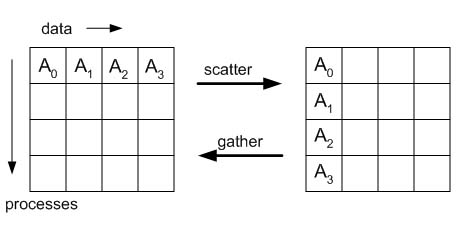
Pseudo-Implementation:
int MPI_Gather(send_buf, send_count, send_dtype, recv_buf, recv_count, recv_dtype, root, comm){
// declare variables
int my_rank, comm_sz;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// receive items from all processes and store them
if(my_rank==root){
for(int i=0; i<comm_sz; i++){
MPI_Recv((dtype*) &recv_buf+i*(recv_count), recv_count, recv_dtype, i, 0, comm, MPI_STATUS_IGNORE);
}
}
// all processes: send an item to the root process
else{
MPI_Send(send_buf, send_count, recv_dtype, root, 0, comm);
}
return MPI_SUCCESS;
}
MPI_Scatter
- one-to-many
- the data of one process is divided among all the processes
Pseudo-Implementation:
int MPI_Scatter(send_buf, send_count, send_dtype, recv_buf, recv_count, recv_dtype, root, comm){
// declare variables
int my_rank, comm_sz;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// root process: send items to all processes
if(my_rank==root){
for(int i=0; i<comm_sz; i++){
MPI_Send((dtype*) &send_buf+i*(send_count), send_count, send_dtype, i, 0, comm);
}
}
// all processes: receive items from the root process
else{
MPI_Recv(recv_buf, recv_count, recv_dtype, root, 0, comm, MPI_STATUS_IGNORE);
}
return MPI_SUCCESS;
}
MPI_Alltoall
- many-to-many
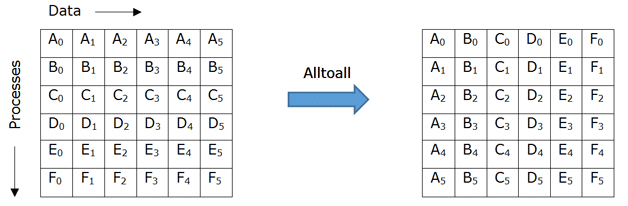
Pseudo-Implementation:
int MPI_Alltoall(send_buf, send_count, send_dtype, recv_buf, recv_count, recv_dtype, comm){
// declare variables
int my_rank, comm_sz;
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
// get the number of processes
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
// all processes: send and receive items from all processes
for(int i=0; i<comm_sz; i++){
for(int j=0; j<comm_sz; j++){
MPI_Sendrecv(
(dtype*) &send_buf+i*(send_count), /* send_buf */
send_count, /* send_count */
send_dtype, /* send_dtype */
j, /* dest */
0, /* send_tag*/
(dtype*) &recv_buf+i*(recv_count), /* recv_buf*/
recv_count, /* recv_count */
recv_dtype, /* recv_dtype */
i, /* source */
0, /* recv_tag */
comm, /* comm */
MPI_STATUS_IGNORE); /* status */
}
}
return MPI_SUCCESS;
}
MPI_Allgather
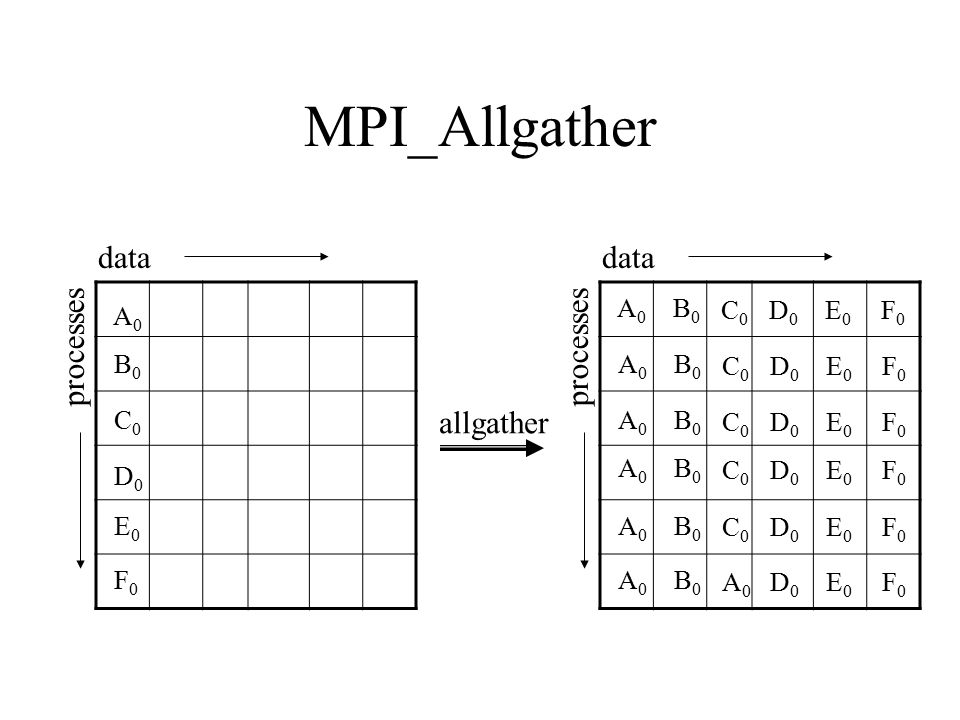
To build this function, we can just combine the following two functions:
- MPI_Gather to Master (implementation above)
- MPI_Bcast from Master to all others (implementation above)
References
- Based on the University of Saskatchewan’s CMPT851: slides for MPI, OpenMP and more.