OMP: parallel computing 2/2
Introduction
The Open Multiprocessing (OpenMP) library is a set of functions and compiler directives for C, C++ and Fortran, designed to run with multiple threads on shared memory machines.
The idea is that we have a serial program as the basis and can incrementally parallelize it (using #pragma omp compiler directives).
Structure of an OpenMP program
Parallel OpenMP programs have a master thread (thread with rank 0) that runs the entire time and slave threads (all other threads) that are forked/joined in parallel sections (see image below). Together all threads form a team. It is usually recommended to leave thread-unsafe operations like I/O to the master thread.
Note that every time the processes join at the end of a parallel section, they first have to synchronize (that means waiting for all threads to reach the barrier; this is done via an implicit barrier, e.g. at the end of every work-sharing construct).
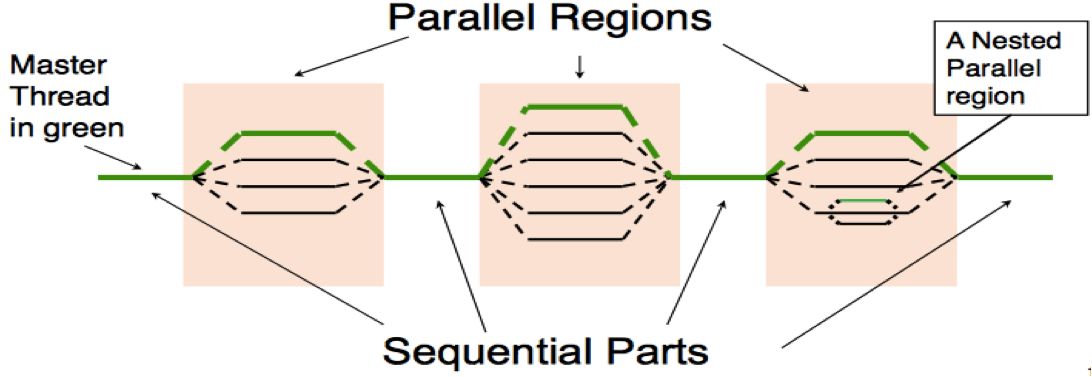
Program execution
You can compile your program using
gcc -g -Wall -fopenmp program.c -o program
where -fopenmp is required to build the program (the other two flags are optional, but can be helpful: -g for more debug info and -Wall for more warnings).
and run it without any special commands:
./program
Rank
To get the rank of a thread, you can use the omp_get_thread_num() function.
int my_rank = omp_get_thread_num();
Thread_count
Similarly, we can obtain the number of threads using the omp_get_num_threads() function.
int thread_count = omp_get_num_threads();
We could also read the thread count via &argv input:
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char** argv)
{
int thread_count = strtol(argv[1], NULL, 10); /* read the first arg (base=10) */
}
Compiler directives (pragmas)
Parallel section
The most widely used pragma is for the parallel section, where we want to execute a block of code in parallel (by multiple threads).
#pragma omp parallel num_threads(thread_count)
{
// local (private) variables
int my_rank = omp_get_thread_num();
double local_result;
// calculate stuff...
// e.g. use part of some input data like data[my_rank]
}
Critical
When writing to shared variables in a parallel section, we have to carefully handle race conditions, e.g. via a critical section that ensures mutually exclusive access to the shared variable:
double total_area = 0;
#pragma omp parallel num_threads(thread_count)
{
// local (private) variables
int my_rank = omp_get_thread_num();
double local_result;
// calculate stuff...
// add the partial result to the total result with mutually exclusive access
#pragma omp critical
{
total_result += local_result;
}
}
Variable scopes
| scope | description | how to init |
| shared | Can be seen by all threads | Outside of parallel sections or explicitly with shared(variable). Also static variables are always shared. |
| private | Can only be seen by one thread | Inside of parallel sections or explicitly with private(variable). |
| firstprivate | same as private, but will init the value of the local variable with the value that the shared variable from before the parallel section has | firstprivate(variable) |
| lastprivate | same as private, but will set the value of the shared variable after the parallel section to the local value that it has in the last iteration in the parallel section | lastprivate(variable) |
Scheduling
#pragma omp parallel (...) schedule(type, chunksize)
- default:
schedule(static, 1)$\rightarrow$ good if all tasks take the same time - worth trying:
schedule(dynamic, 1)$\rightarrow$ good if tasks have a lot of variation in runtime
| type | description |
| static | schedule assigned before loop is executed |
| dynamic | after a thread completes its current chunk, it can request another |
| auto | schedule determined by compiler |
| runtime | schedule determined at runtime |
Reduction
If you use the #pragma omp parallel (...) reduction(op:result) statement, the result variable will have a local scope within the parallel block. At the end of the parallel block, it will be reduced automatically using the specified operation op and stored in the same result variable (which is shared after the parallel block).
Common operations for reduction are +, *, &, and |.
Example call:
int thread_count = 2;
int total_result = 4;
#pragma omp parallel num_threads(thread_count) reduction(*:total_result)
{
// calculate stuff..
total_result = 5 + 5; /* partial result of each thread */
}
printf("result: %d\n", total_result);
The result is 4 * 10 * 10 = 400. The first factor (4) is the value that the result had before the parallel section. This is multiplied by the partial (local) results in each thread (here 5+5). So in a typical usecase where you just want to multiply the partial results, you should declare the variable as int total_result = 1 beforehand and similarly for addition you would use int total_result = 0.
Sample OpenMP program
Combining everything, we get the following program.
#include <omp.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char** argv){
int thread_count = 4; /* shared */
int total_result = 0; /* shared */
printf("hi from master in the serial section!\n");
#pragma omp parallel num_threads(thread_count)
{
// local (private) variables
int my_rank; /* private */
int partial_result = 0; /* private */
// get the threads rank
my_rank = omp_get_thread_num();
// print the rank
printf("hi from thread %d of %d!\n", my_rank, thread_count);
// calculate stuff
for(int i=0; i<1000; i++){
partial_result++;
}
// add the partial result to the total result
// with mutually exclusive access to avoid a race condition
#pragma omp critical
{
total_result += partial_result;
}
}
// master (rank 0): print result
printf("result: %d\n", total_result);
return 0;
}
hi from thread 0 of 4!
hi from thread 3 of 4!
hi from thread 1 of 4!
hi from thread 2 of 4!
result: 4000
Shared work constructs
Parallel for-loop
In the following program, we are splitting a for loop (also known as work sharing) using the directive #pragma omp parallel for and a reduction at the end.
Note:
- the number of iterations has to be clear at the start (while loops and for loops with a break cannot be parallelized)
- be aware of
data dependencies(if any variables are accessed via write or read in different iterations, the code will compile but yield wrong results)
#include <omp.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char** argv){
int thread_count = 24; /* shared */
int total_result = 0; /* reduction variable */
#pragma omp parallel for num_threads(thread_count) \
reduction(+: total_result) shared(thread_count) schedule(static, 1)
// shared work construct: partition the for-loop
// into (n/thread_count) iterations per process
// and reduce the individual results with a sum at the end
for(int i=0; i<thread_count; i++){
total_result++;
}
// note: there is an implicit barrier at the end
// of shared work constructs (here)
// master (rank 0): print result
printf("result: %d\n", total_result);
return 0;
}
Measuring execution time
We can measure the time with the omp_get_wtime() function by calling it at the start and at the end of the program.
The execution time is then the difference between the two timepoints: execution_time = end_time - start_time.
#include <omp.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char** argv){
double start_time = omp_get_wtime();
int x = 10;
// calculate stuff
for(int i=0; i<2000000000; i++){
x = x*x;
}
double end_time = omp_get_wtime();
// print the time diff
printf("execution time: %f seconds\n", end_time - start_time);
return 0;
}
References
- Based on the University of Saskatchewan’s CMPT851: slides for MPI, OpenMP and more.
- OpenMP logo.
- OpenMP program structure image.
{kind=link}
{kind=link}