The Prioritized Experience Replay Buffer
Complete set of keywords: reinforcement learning, memory, dataset, dreaming.
This is a draft for a research idea.
Todo
- read Daniel Takeshis blogpost about Understanding Prioritized Experience Replay
- read the catastrophic inference wiki article for pointers to other research on how to prevent it
Intro
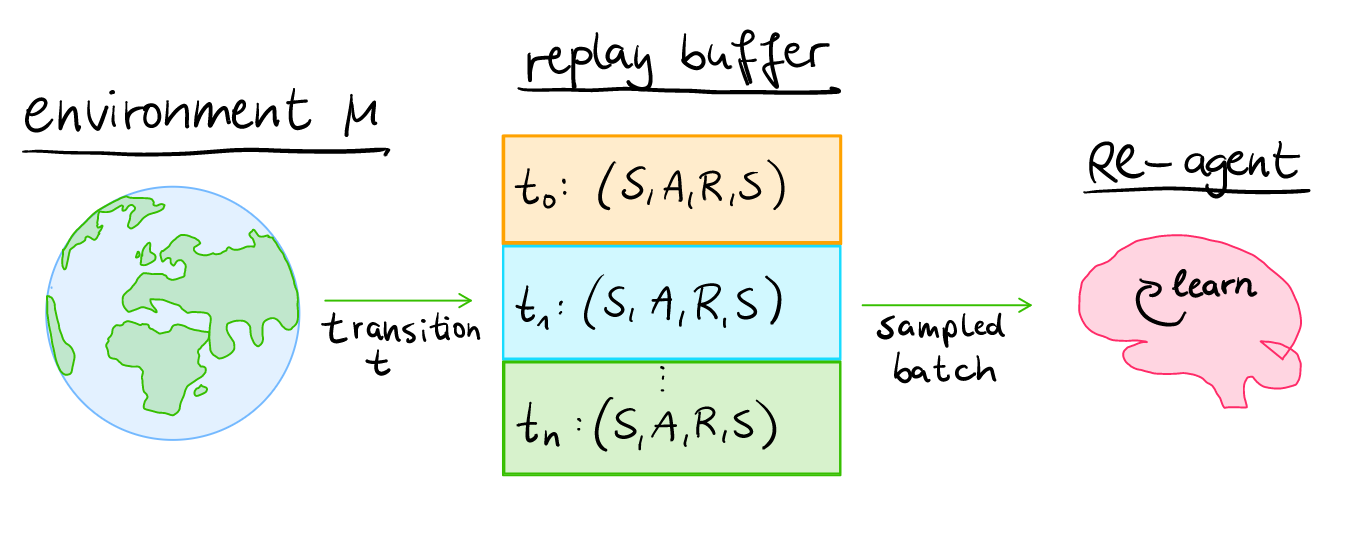
Prioritized Experience Replay (PER) is a technique that was introduced by [5] Schaul et al. in 2015. The method aims to improve the performance of the Experience Replay (ER) buffer that lets Reinforcement Learning agents learn quicker by replaying transitions that were observed by another (old) policy (=off-policy learning). The idea is to sample experiences in the buffer with a probability that is proportional to the TD-error of the experience, because we can learn the most from transitions that have a high TD-error (where the agents prediction was the most off the target).
Replay buffers resemble some similarity to humans learning in their sleep by replaying important series of transitions (=dreaming) that were experienced during the day to consolidate them into long-term memory [7] and learn from them to develop problem-solving skills [8].
\[\begin{align*} \text{Experience Replay} \; &\hat{=} \; \text{Dreaming} \\ &\hat{=} \; \text{Consolidation of new knowledge into long-term memory (and quicker learning)} \end{align*}\]Right now, the long term memory is only represented by the Neural Network, but maybe we can mimick a long-term memory by compressing experiences into a seperate long-term memory buffer that the Neural Network relearns from.
Discussion
I would argue that complex architectures aimed at mitigating catastrophic forgetting, such as the dual-memory architecture (short-term and long-term) of [6] Atkinson et. al. are not necessary if the following conditions are met:
- the short-term learning is achieved through learning from the (prioritized) replay buffer (or could also be achieved by combined experience replay, where the agent learns from stored experiences in the replay buffer sometimes and other times from fresh experiences of the latest episode) ✔️
- the long-term knowledge is distilled in the neural network ✔️
- (the critical component, missing from current architectures): relearn old (compressed) knowledge in order to avoid catastrophic forgetting (CF) or ensure that this knowledge isn’t forgotten
Catastrophic forgetting could occur for example when good policy experiences only ‘good states’ and theirfore unlearns what good behavior would look like in ‘bad states’ (e.g. the agent is about to crash into an obstacle). If the (good) policy then encounters a bad state that is not often experienced by the policy, this could lead to unpredictable (and probably bad) behavior following this state, e.g. you could imagine a car that slides too close to the edge of the road on wet ground and then doesn’t know how to recover from this situation because it only knows the middle of the road, where it usually is. Or for a simple environment like cartpole, this would be a state where the pole is almost falling, and a good policy that usually only experiences states where it holds the pole upright wouldn’t know how to recover properly. This phenomenon is the result of the replay buffer filling up with only ‘good experiences’ (no bad states like the cartpole almost tiping over are present in the buffer), because the bad (exploratory) experiences got pushed out of the buffer by newer experiences.
My idea now is to still keep some old experiences in order to mitigate this catastrophic forgetting (unlearning good behavior for states that are not encountered, because the policy doesn’t select trajectories that lead to these states often). To do this efficiently, you could do one of the following:
- try to compress the old experiences to get some kind of basis for long-term memory (the agent continuously relearns from these old experiences)
- find a good heuristic for which old states should be kept inside the buffer and not thrown away like in normal (prioritized) experience replay buffers.
For that to work, we need to ensure that old (long-term) knowledge isn’t forgotten by the network because the corresponding experiences got pushed out of the replay buffer by newer experiences. Theirfore our goal is to capture the entire data distribution in the replay buffer, so that the policy doesn’t suffer from catastrophic forgetting, while not slowing down the learning of new knowledge by much.
Proposed solutions
We can achieve this goal by compressing old experiences into new (much fewer!) experiences that the agents relearns from (if we compress multiple experiences into one and learn from this single datapoint multiple times, we have to be really careful about not overfitting to this single point), or we could introduce a new parameter to balance the tradeoff between throwing out old actions and having a diverse buffer (dataset).
-
when learning from old policies, we have to use the probability of taking that action of current policy.
-
we want to capture the entire distribution while favoring newer data, theirfore we need a mechanism that measures the similarity of new data compared to the old data and a bonus for freshness
-
tradeoff between freshness of data and dis-similarity between that piece of data compared to the entire dataset (we can approximate the distribution of the dataset by the current entries of the replay buffer or by the knowledge compressed in the neural network (question: how could you do that?) ) (capturing edge-cases that might be more important to remember) After the replay buffer is filled up, we need a measure how similar a new experience/episode is to all experiences/episodes in the buffer. We have to calculate all of the TD-Errors from the perspective of our current policy (for that, we use $V(s)$ and $V(s’)$).
How can you measure the similarity of datapoints (experiences)?
- first idea: learn an embedding function and compare the vectors, e.g. by the cosine-similarity function
Experiences that want to throw away first:
- old data (> include an episode-index for each experience to know how fresh or old the experience is)
- data with a low TD-Error from the current policy
- data that is represented often in the dataset and theirfore has a high sum of similarities to each other datapoint in the buffer
References
- Thumbnail & Zhang, Sutton’s paper summarized at endtoend.ai: Paper Unraveled: A Deeper Look at Experience Replay (Zhang and Sutton, 2017).
- TheComputerScientist (YouTube): How To Speed Up Training With Prioritized Experience Replay
- endtoendai - one-slide-summary: Revisiting Fundamentals of Experience Replay
- Shangtong Zhang, Richard S. Sutton: A Deeper Look at Experience Replay
- Schaul, Quan, Antonoglou and Silver (2015): Prioritized Experience Replay
- Atkinson et. al. Pseudo-Rehearsal: Achieving Deep Reinforcement Learning without Catastrophic Forgetting
- Wiki: Sleep and leaning
- Wiki: Dreams